Bài toán “text to image” – “tạo hình ảnh tử văn bản” – đã được giới thiệu lần đầu tiên vào năm 2015 sử dụng mô hình RNN – recurrent neural network. Trải qua nhiều năm, nhiều điểm cải tiến đã được áp dụng, đặc biệt phải kể đến sự xuất hiện của mô hình Transformer để giải quyết nhiều bài toán xử lý ngôn ngữ hiện nay. Đặc biệt hơn, dưới sự bùng nổ của dữ liệu và gia tăng kích thước của các mô hình Transformers, ta có thể chiêm ngưỡng những kết quả ấn tượng trong bài toán “text to image” trong hơn 1 năm qua, đặc biệt là từ OpenAI.
DALL-E (2021)
Vào tháng 1/2021, OpenAI đã giới thiệu hệ thống DALL-E – một mạng nơ-ron có khả năng tạo ra bất kỳ hình ảnh nào dựa trên các văn bản mô tả. DALL-E có nhiều khả năng đa dạng như tạo ra các hình ảnh nhân hóa của động vật và vật thể, kết hợp các khái niệm tưởng như không liên quan một cách đầy sáng tạo, và chỉnh sửa các hình ảnh có sẵn.




DALL-E bao gồm 2 thành phần: một “bộ tự mã hoá rời rạc” (discrete autoencoder) học cách biểu diễn hình ảnh trong một chiều không gian tiềm ẩn (latent space), và một mô hình Transformer học sự tương quan giữa ngôn ngữ và sự biểu diễn của hình ảnh.
Vector Quantized Variational Autoencoder (VQ-VAE)
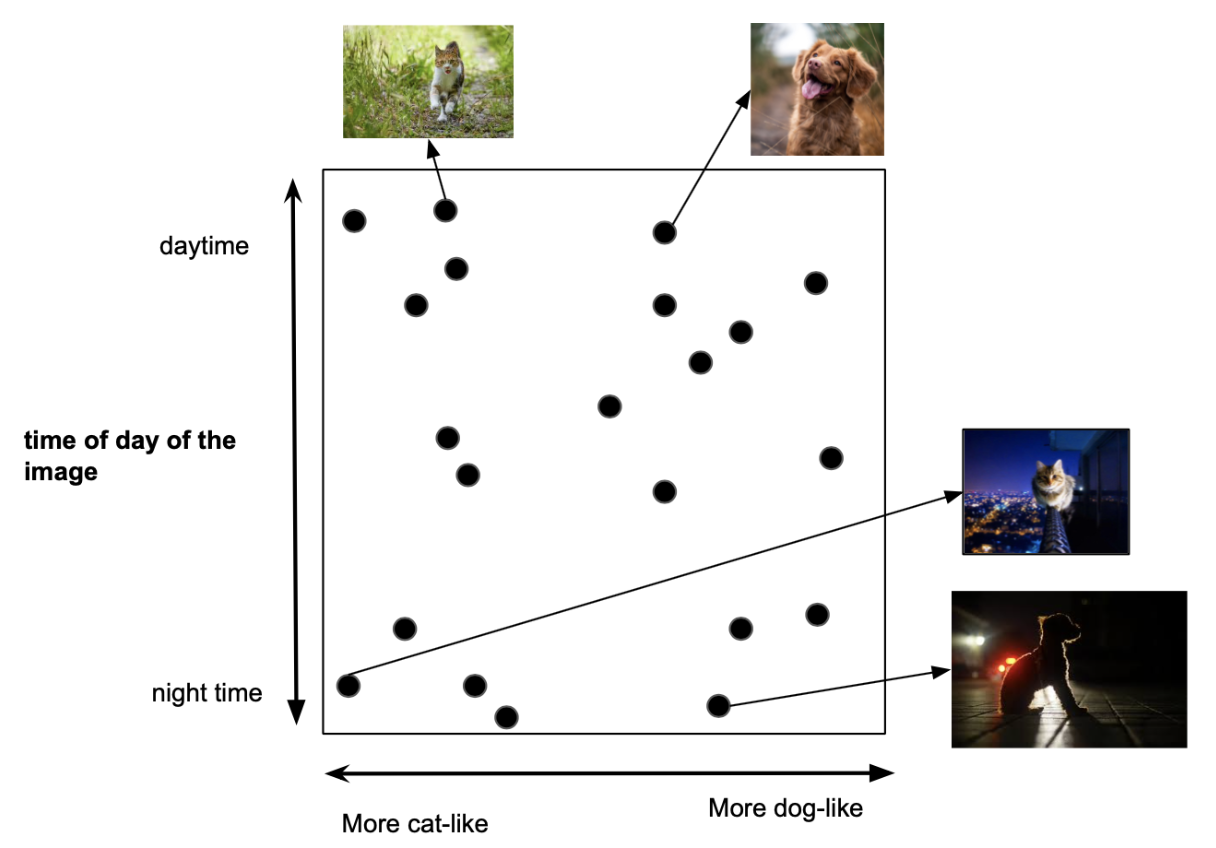
VQ-VAE là thuật toán giúp DALL-E sinh ra những hình ảnh vô cùng chân thực, nhưng trước hết, chúng ta cần hiểu rõ về khái niệm latent space. Latent space là một dạng biểu diễn ẩn của một phân phối giữ liệu. Ví dụ, biến $x\in \mathbb{R}$ thuộc không gian $n$ chiều được xác định qua 1 biến đổi tuyến tính $x=Az+b$ từ biến $z\in\mathbb R$ thuộc không gian $m$ chiều với $m$ < $n$. Trong phần lớn trường hợp, chúng ta chỉ nhìn thấy dữ liệu của $x$ chứ không tiếp cận được $z$ ở chiều không gian “ẩn”. $z$ là biểu diễn cơ bản và tinh gọn hơn của $x$ và cũng là đầu vào vô cùng hữu ích của nhiều thuật toán tối ưu hoá. Hãy thử xem qua minh hoạ giản lược dưới đây. Các hình ảnh có thể được biểu diễn ở một không gian ẩn gồm 2 chiều: thời gian trong ngày và hình ảnh sư giống nhau giữa động vật trong ảnh và chó/mèo.
Bộ tự mã hoá (autoencoder) là một phương pháp học không giám sát (unsupervised learning) sử dụng mạng nơ-ron (neural network) để tìm biểu diễn hình ảnh ở không gian tiềm ẩn (latent space representation). Mô hình này gồm 2 thành phần:
- Mạng mã hoá (encoder network) có nhiệm vụ học biến đổi phi tuyến tính (non-linear transformation) $z=f(x)$ từ không gian dữ liệu đầu $x$ vào (input space) sang không gian tiềm ẩn (latent space).
- Mạng giải mã (decoder network) có nhiệm vụ học cách tái tạo (reconstruct) dữ liệu đầu vào (input) từ một biểu diễn $z$ ở không gian tiềm ẩn, qua $\hat x = g(z)$, với $x$ là kết quả tái tạo.
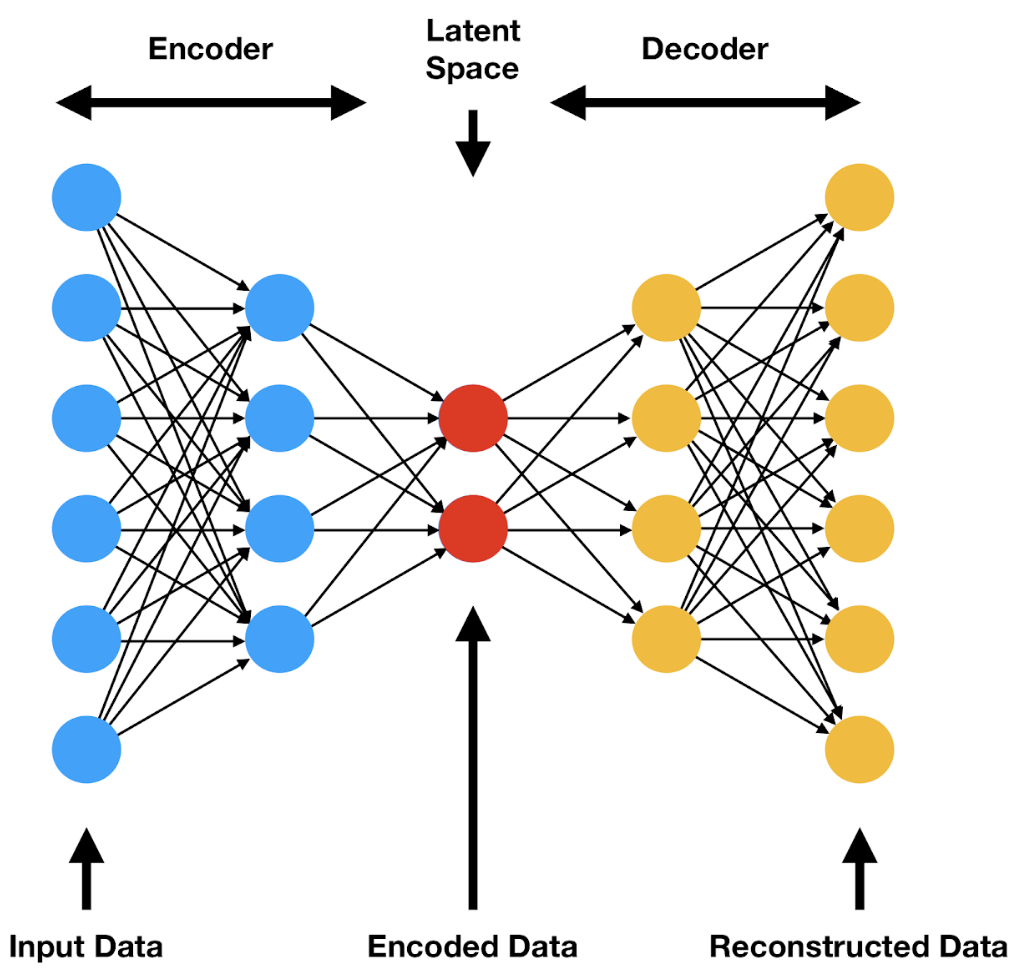
2 thành phần này của autoencoder được tối ưu hoá với mục tiêu giảm mất mát tái tạo (reconstruction loss) giữa dữ liệu đầu vào $x$ và kết quả tái tạo $\hat x$. Sau khi được tối ưu hoá, decoder có thể được sử dụng độc lập như một công cụ sinh hình ảnh (image generation) dựa trên biểu diễn tuỳ chọn ở không gian ẩn. DALL-E sử dụng bộ mã hoá rời rạc (discrete autoencoder) với ràng buộc rằng biểu diễn ở không gian ẩn phải mang giá trị rời rạc. Các bạn có thể đọc thêm chi tiết về phiên bản autoencoder tiên tiến hơn được dùng trong DALL-E qua bài viết sau.
Language Models từ Transformer
Nếu autoencoder giúp DALL-E chỉ học sự biểu diễn của hình ảnh thì transformer là thành phần giúp DALL-E học sự tương quan giữa ngôn ngữ đầu vào và biểu diễn của hình ảnh. Mô hình transformer lần đầu được áp dụng vào bài toán dịch máy (machine translation) với mục tiêu sinh văn bản (text generation). Tương tự như autoencoder, transformer cũng bao gồm 2 thành phần mã hoá (encoder) và giải mã (decoder) là các mạng nơ-ron nhiều lớp.
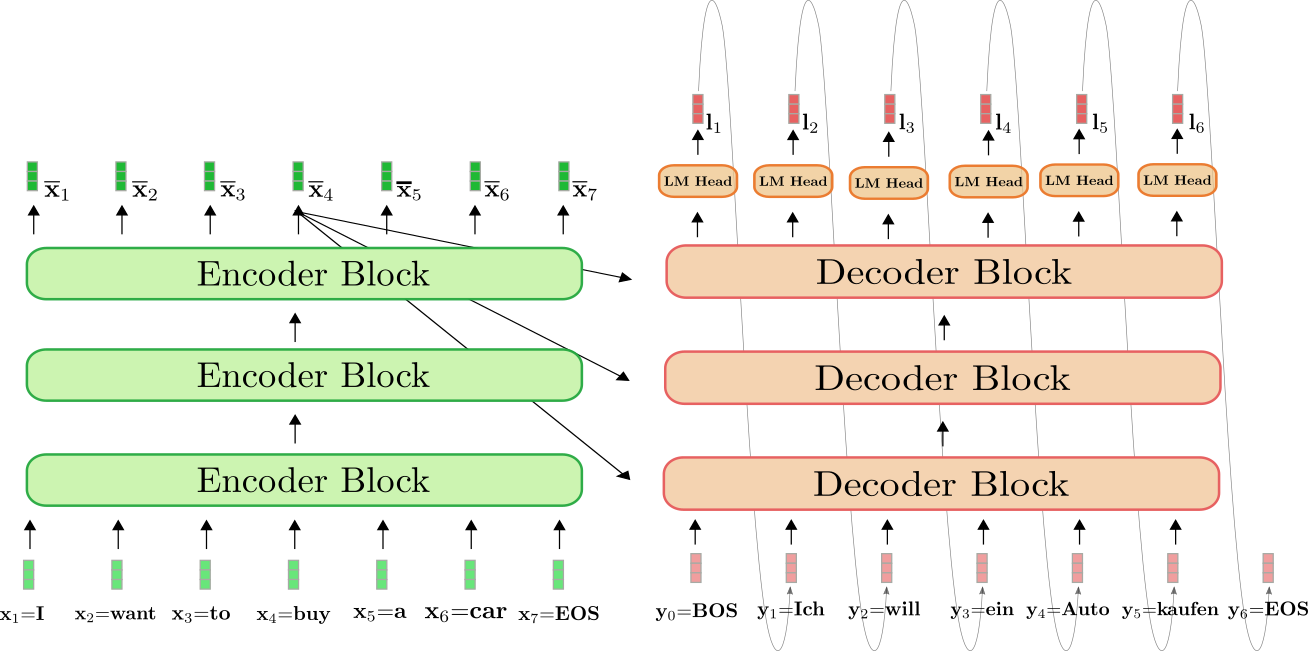
Trong thành phần transformer của DALL-E, ngôn ngữ đầu vào được đưa vào encoder với mục tiêu sinh 1 chuỗi các biến rời rạc ở decoder. Chuỗi các biến rời rạc này có thể được ánh xạ (mapped) thành biểu diễn của ngôn ngữ ở không gian tiềm ẩn của autoencoder. Sau khi qua xử lý, biểu diễn này là đầu vào decoder của autoencoder với đầu ra là hình ảnh đúng như mô tả của ngôn ngữ.
DALL-E 2 (2022)
Chỉ sau 1 năm, OpenAI đã ngay lập tức giới thiệu mô hình mới DALL-E 2 có thể tạo ra hình ảnh chân thực hơn với độ phân giải cao gấp 4 lần phiên bản trước đó. DALL-E 2 đã học được mối quan hệ giữa các hình ảnh và văn bản được sử dụng để mô tả chúng. Nó sử dụng một quá trình được gọi là “khuếch tán” (diffusion), bắt đầu với một mẫu các chấm ngẫu nhiên và dần dần thay đổi mẫu đó thành hình ảnh khi nó nhận ra các khía cạnh cụ thể của hình ảnh đó. Các bạn có thể xem những bức ảnh dưới đây do DALL-E 2 tạo ra so với DALL-E.

Ngoài ra, DALL-E 2 có thể tạo các ảnh biến thể lấy cảm hứng từ một ảnh gốc.

Như các bạn đã thấy, tiềm năng của DALL-E trong việc sáng tạo nội dung trong tương lai là không thể phủ nhận. Với tốc độ nghiên cứu hiện nay, có lẽ chúng ta sẽ sớm thấy các phiên bản kế tiếp và không biết nó sẽ còn thú vị như thế nào nữa!